Si vous évaluez Stable Audio pour des fonctionnalités de produit, des pipelines de contenu ou des outils créatifs, vous avez généralement trois questions : que peut-il générer, où se trouve la documentation de l’API Stable Audio et à quoi ressemblera la tarification de l’API Stable Audio à l’échelle. Ce guide passe en revue ces décisions avec une optique axée sur le développeur, y compris un flux pratique de l’API Stable Audio 2.5 et une manière prudente de vérifier la tarification spécifique à la version, telle que la tarification de Stable Audio 2.0 en 2026. Conclusion en 3 lignes
Les sections ci-dessous se concentrent sur les parties qui comptent généralement une fois que vous avez dépassé la page d'accueil : comment Stable Audio est exposé à travers différentes surfaces, ce qu'il faut lire en premier dans la documentation, comment penser à la tarification et où les questions spécifiques à la version nécessitent une vérification supplémentaire.
Point clé en 3 lignes
Commencez par la documentation du fournisseur (auth → schéma de requête → async/streaming → erreurs) avant d'ajuster les invites.
Budgétisez en fonction de ce que le fournisseur facture (crédits, durée, tentatives), et non pas selon le principe « une requête = un coût ».
Considérez le « prix Stable Audio 2.0 2026 » comme une tâche de vérification : confirmez les ID de modèle et le tableau des prix sur la plateforme que vous utilisez réellement.
Aller à
Qu'est-ce que Stable Audio et que pouvez-vous générer avec cet outil aujourd'hui ?
D'un point de vue pratique, Stable Audio est un système de génération audio que vous pouvez utiliser pour créer de courtes idées musicales, des éléments de conception sonore et des variations, soit à partir de texte seul, soit en transformant de l'audio existant, selon la surface du produit et l'API que vous intégrez. La plupart des équipes l'évaluent pour : le prototypage rapide, les variantes de contenu (publicités, réseaux sociaux), les esquisses de SFX/musique de jeux, et les outils de création où la latence et le coût sont importants.
Dans l'utilisation quotidienne, vous verrez généralement deux grands modes de génération :
Texte-vers-audio : vous décrivez ce que vous voulez (genre, instruments, ambiance, tempo, mixage), et le modèle génère un nouvel audio.
Audio-vers-audio : vous fournissez un clip audio d'entrée et demandez une transformation (variation, changement de style, modifications de type remplissage, ou "même idée, production différente"), sous réserve de ce que votre point de terminaison choisi prend en charge.
Pour une présentation canonique du produit et tout positionnement officiel concernant les capacités, commencez par la page d'accueil de Stable Audio sur Stability AI : Stable Audio par Stability AI. À partir de là, déterminez si vous êtes un créateur solo (l'interface utilisateur interactive peut suffire) ou un développeur/une équipe (vous aurez besoin d'un chemin de fournisseur d'API avec une facturation, des limites de débit et des attentes de support prévisibles).

Stable Audio « partenaires » vs « API officielle » : quelle est la différence pour les développeurs ?
Les développeurs sont souvent confrontés à une confusion, car « Stable Audio » est accessible via différents points d'entrée : les propres interfaces de produits de Stability AI, une API officielle et des plateformes partenaires qui hébergent ou exposent des modèles en tant que points de terminaison gérés. La différence est importante pour tout ce qui vous intéresse en production : authentification, quotas, observabilité, nouvelles tentatives et affichage des prix.
Une façon simple d'y penser :
Un exemple concret de style partenaire est l'expérience de liste de modèles que vous verrez sur des fournisseurs tels que fal (utile pour comprendre rapidement le type de point de terminaison et l'affichage des prix) : Page du modèle Stable Audio 2.5 (audio-vers-audio).
Avant d'écrire du code, décidez sur quelle « surface » vous effectuez la livraison (officielle ou partenaire). Ensuite, verrouillez l'ID de modèle + l'URL de la page de tarification + l'URL de la documentation dans le fichier README de votre projet afin que votre équipe puisse toujours vérifier ce qui est déployé.
Où trouver la documentation de l'API Stable Audio (et quoi lire en premier)
Si votre objectif immédiat est la documentation de l'API Stable Audio, commencez par la référence spécifique au fournisseur pour le point de terminaison que vous prévoyez de livrer. Par exemple, si vous intégrez un point de terminaison partenaire, vous pouvez commencer par la référence de l'API ici : Documentation de l'API audio-vers-audio Stable Audio 2.5.
Que lire en premier (dans l'ordre) pour éviter de perdre des heures :
Authentification : comment les clés API sont transmises, quels en-têtes sont requis et comment fonctionnent les étendues/autorisations.
Schéma de requête : noms de champs exacts, types de données, valeurs min/max (les limites de durée sont souvent la première surprise).
Schéma de réponse : où apparaît l’URL/blob audio de sortie, ainsi que toutes les métadonnées dont vous avez besoin pour l’attribution/la journalisation.
Asynchrone vs synchrone : si la génération est mise en file d’attente et nécessite un sondage/des rappels, et combien de temps les résultats restent disponibles.
Codes d’erreur et limites de débit : en particulier les erreurs d’authentification 401/403, la limitation 429 et le comportement de délai d’attente.
Considérez la documentation comme la source de vérité pour les noms et les valeurs par défaut des paramètres ; même de petites différences (secondes vs millisecondes, duration vs duration_seconds) peuvent entraîner des échecs déroutants.
Authentification et clés API : les pièges courants à éviter avant votre première requête
La plupart des problèmes de type « ma première requête a échoué » ne sont pas des problèmes de modèle, mais des problèmes d'authentification, d'environnement ou de quota. Utilisez cette liste de contrôle avant de déboguer les invites.
Liste de contrôle pré-vol
Stockez la clé API dans une variable d'environnement (évitez de la coder en dur dans les référentiels ou les applications clientes).
Confirmez que la clé est pour l'espace de travail/projet correct (les équipes en ont souvent plusieurs).
Vérifiez que l'accès au modèle est activé (certains fournisseurs limitent certains modèles, régions ou niveaux).
Vérifiez les limites d'utilisation/crédits avant de tester la charge (un arrêt soudain peut ressembler à un bug réseau).
Assurez-vous que l'horloge de votre serveur est précise si le fournisseur utilise des signatures temporelles (varie selon le fournisseur).
Erreurs courantes → causes probables → correctifs rapides
Étant donné que les limitations peuvent différer entre les surfaces officielles et celles des partenaires, vérifiez toujours les documents de point de terminaison exacts que vous appelez.

Bases du schéma de requête : prompt, durée et audio d'entrée (audio-vers-audio)
Dans la documentation de l'API Stable Audio, les champs les plus importants sont ceux qui déterminent (a) ce qui est généré et (b) combien vous payez. Bien que les noms exacts varient selon le fournisseur, vous verrez couramment :
prompt: votre description textuelle (genre + instrumentation + ambiance + structure + notes de mixage).duration/duration_seconds: durée de sortie cible. Cela affecte souvent le coût et la durée d’exécution.input_audio(audio vers audio) : soit un chargement, une URL ou une charge utile base64, plus des paramètres facultatifs qui contrôlent la force avec laquelle la sortie adhère à l’entrée (les noms de champs diffèrent).Contrôles facultatifs seed / randomness : si pris en charge, ils aident à reproduire les sorties ; si non pris en charge, vous utiliserez des astuces de cohérence au niveau du flux de travail (traitées ci-dessous).
Une "forme" minimale pour une requête audio-vers-audio (pseudo-structure ; vérifiez les clés exactes dans la documentation de votre point de terminaison) :
Définissez
API_KEYdans votre environnementEnvoyez une requête avec :
prompt: « Lo-fi hip hop beat, warm vinyl noise, 85 BPM, mellow keys, tight kick »duration_seconds: 15input_audio: votre référence de clip (URL/téléversement/base64 selon la documentation)Recevez une réponse contenant :
une URL audio de sortie ou une référence de fichier
un ID de requête/tâche pour le suivi (en particulier pour l’asynchrone)
Évitez de vous fier aux valeurs par défaut non documentées. Si la documentation n'indique pas clairement une valeur par défaut (pour la durée, la fréquence d'échantillonnage ou l'intensité), définissez-la explicitement dans votre requête afin que le comportement en production ne change pas lorsque le fournisseur effectue des mises à jour.

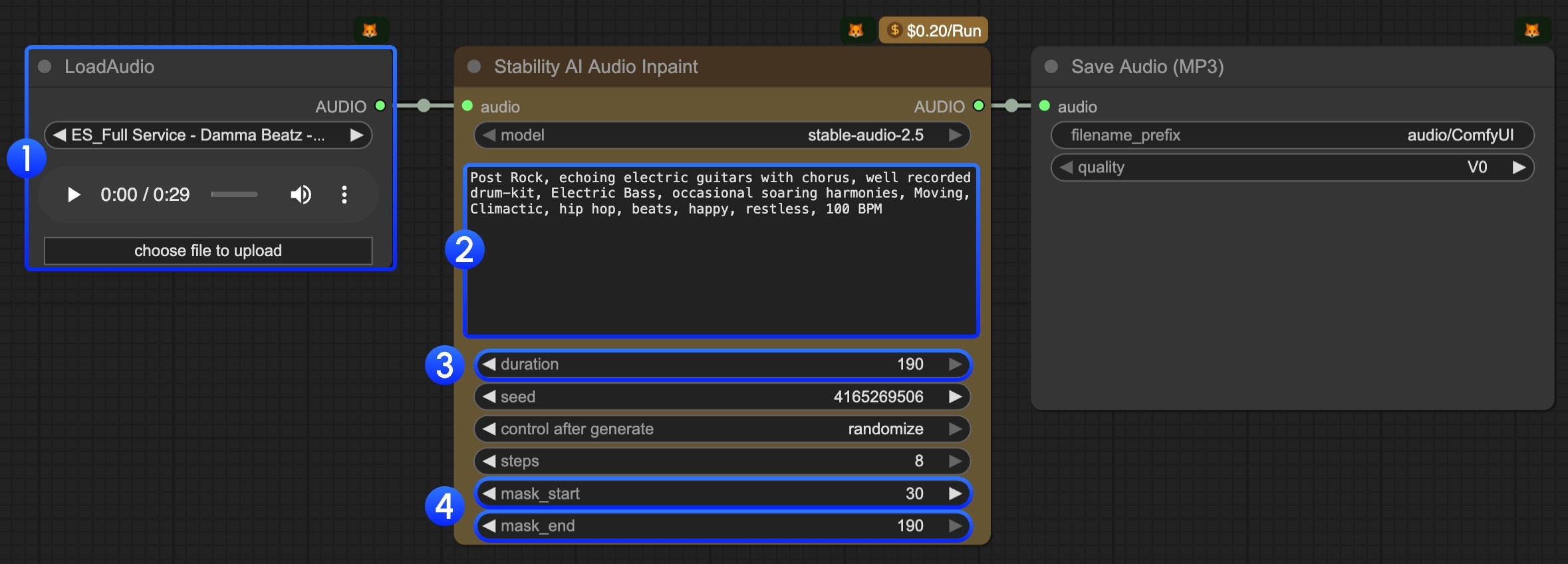
Comment appeler l'API Stable Audio 2.5 de bout en bout (un flux pratique)
Une intégration API Stable Audio 2.5 prête pour la production ne se limite pas à une simple requête POST, mais concerne davantage le flux de travail environnant : préparation des actifs, contrôle des tâches, téléchargement/stockage et observabilité. Une présentation conceptuelle utile (surtout si vous utilisez des outils basés sur des nœuds) est le tutoriel partenaire ici : Stable Audio dans la documentation Comfy.
Un flux pratique « 0 à 1 » ressemble à ceci :
Préparer les ressources
Si vous effectuez une conversion audio-vers-audio, normalisez le clip d'entrée : volume sonore uniforme, silence supprimé et format/taille pris en charge (les exigences exactes dépendent de la documentation de votre fournisseur).
Précalculez les métadonnées dont vous aurez besoin ultérieurement : identifiant d'utilisateur, version de l'invite, identifiant du modèle et un indicateur de politique de contenu si votre application en possède un.
Soumettre la demande de génération
Stockez la totalité de la charge utile que vous envoyez (moins les secrets) pour le débogage et la reproductibilité ultérieurs.
Joignez une clé d'idempotence si le fournisseur la prend en charge (empêche la double facturation en cas de nouvelles tentatives — spécifique au fournisseur).
Gérer l'exécution asynchrone
De nombreuses générations audio sont mises en file d'attente ; préférez un modèle de tâche asynchrone si disponible.
Implémentez l'interrogation avec temporisation, ou des webhooks/callbacks lorsque cela est pris en charge.
Télécharger et stocker les sorties
Persistez le fichier résultant dans votre propre stockage (S3/GCS/R2) afin de ne pas dépendre des URL temporaires des fournisseurs.
Stockez les métadonnées : version du modèle, paramètres, horodatage et tout champ de type seed.
Réutiliser, itérer et tests A/B
Enregistrez les modèles d'invites et les paramètres « reconnus » pour chaque cas d'utilisation (jingle publicitaire, SFX d'interface utilisateur de jeu, boucle lo-fi).
Générez des variations par lots et choisissez les gagnants en utilisant soit une évaluation humaine, soit des vérifications légères des caractéristiques audio.
Texte-vers-audio ou audio-vers-audio : quel modèle de point de terminaison correspond à votre cas d'utilisation ?
Choisir le bon modèle de point de terminaison est le moyen le plus rapide d'obtenir de meilleurs résultats avec moins de tentatives (et moins de surprises sur votre facture).
Si votre fournisseur propose les deux, il est courant d'utiliser la synthèse vocale pour les premières ébauches, puis l'audio-vers-audio pour « verrouiller » une direction et produire des variantes contrôlées.
Rendre les résultats plus cohérents : graines, itérations et structure des invites
La cohérence est généralement ce qui différencie une démo amusante d'une fonctionnalité livrable. Votre objectif est de réduire le caractère aléatoire des entrées (invite, paramètres, références) afin de ne pas gaspiller votre budget en forçant la solution.
Si votre point de terminaison prend en charge les graines
Persister la seed avec chaque actif généré.
Garder les prompts stables et ne changer qu'une seule variable à la fois (instrumentation, BPM ou ambiance — pas les trois).
Si votre point de terminaison ne prend pas en charge les seeds (ou si le comportement des seeds varie)
Utiliser un modèle de prompt fixe et le contraindre avec des exigences musicales et de mixage claires.
Utiliser l'audio-vers-audio avec un clip de référence cohérent pour ancrer la structure.
Générer par lots un petit ensemble (par exemple, 4 à 8) et choisir la correspondance la plus proche au lieu de régénérer à plusieurs reprises un par un (cela réduit souvent la "dérive" dans votre processus de sélection).
Une structure d'invite réutilisable qui a tendance à rester pertinente :
Style/genre: “minimal techno, ambiance entrepôt”
Tempo & groove: “125 BPM, rythme régulier en quatre temps”
Instrumentation: “grosse caisse serrée, charleston décalé, basse mono”
Ambiance: “sombre, tendue, hypnotique”
Notes de mixage: “basse fréquence percutante, aigus contrôlés, réverbération légère”
Contraintes négatives: “pas de voix, pas de longue introduction, éviter les accords de jazz”
Pour une itération conviviale pour les créateurs, vous pouvez également prototyper des modèles d'invites et des variations dans une application musicale comme MelodyCraft avant de les intégrer en tant que préréglages d'API.
Tarification de l'API Stable Audio : comment les crédits se traduisent en coût réel
Le prix de l'API Stable Audio peut être simple ou déroutant selon la plateforme : certaines facturent par crédits, d'autres affichent le prix par requête, et beaucoup fixent le prix en fonction de la durée de sortie (et parfois des paramètres de qualité). Le point de départ le plus fiable pour les changements de prix officiels et la définition des crédits est l'article de mise à jour de Stability AI : Mise à jour des prix de l'API.
Pour estimer les coûts sans deviner, construisez votre modèle de budget autour de trois questions :
Unité de facturation : crédits, secondes, requêtes ou un modèle hybride ?
Ce qui est considéré comme utilisation : uniquement les générations réussies, ou les tâches ayant échoué/ayant fait l’objet de nouvelles tentatives consomment-elles également des crédits ? (Cela varie selon le fournisseur ; vérifiez dans la documentation de facturation.)
Plafonds et niveaux : durée maximale par appel, simultanéité et si les niveaux supérieurs débloquent un meilleur débit.
Une méthode d'estimation simple que vous pouvez appliquer dès aujourd'hui :
Déterminez votre durée moyenne demandée (par exemple, 10 s, 15 s, 30 s).
Déterminez votre taux de nouvelle tentative prévu (par exemple, 5 à 15 % au début de la production ; réduisez-le à mesure que vous améliorez les invites et la validation).
Multipliez par le tableau de crédit par unité de votre fournisseur et appliquez une mémoire tampon.
Tableau d'exemple de gamme de coûts (insérez les chiffres de votre fournisseur)
La clé est que « 1 000 générations » n'est pas un nombre de coût tant que vous n'avez pas défini la durée, le type de point de terminaison et le comportement de nouvelle tentative.
Prix de la conversion texte-audio vs audio-audio : ce qu'il faut vérifier avant de se lancer
Même lorsque les deux modes sont disponibles, le texte-vers-audio vs audio-vers-audio peuvent être tarifés différemment (ou avoir des limites différentes). Avant de livrer, effectuez cette vérification en 7 points afin de ne pas découvrir l'économie unitaire en production.
Liste de contrôle de lancement (tarification + limites)
Confirmer le(s) point(s) de terminaison exact(s) que vous appellerez et leur prix unitaire (crédits/secondes/requêtes).
Confirmer la durée maximale par requête et si un audio plus long nécessite un découpage.
Confirmer les limites de concurrence (requêtes par minute, tâches parallèles).
Confirmer les règles de facturation en cas d'échec et de nouvelle tentative (spécifiques au fournisseur ; ne pas supposer).
Confirmer si la bande passante de téléchargement/téléversement audio affecte le coût (généralement séparé, mais variable).
Confirmer si les paramètres de "qualité" ou de "pas/itérations" modifient le prix (si exposés).
Confirmer la fenêtre de rétention de la sortie (combien de temps le fournisseur héberge le fichier généré).
Si l'un des points ci-dessus n'est pas explicitement mentionné dans la documentation, considérez-le comme un risque et testez-le avec un petit pilote payant.
Exemple de tarification des fournisseurs : ce que « 0,2 $ par audio » signifie en pratique
Sur certaines plateformes partenaires, vous verrez une simple étiquette comme « 0,2 $ par audio ». La bonne façon d'interpréter cela est la suivante : « 0,2 $ par requête selon les hypothèses par défaut pour ce point de terminaison ». Votre coût réel peut être supérieur ou inférieur selon ce que le fournisseur considère comme une unité facturable.
Utilisez l'affichage des prix de la page du modèle comme point de départ, puis validez par rapport aux documents de facturation et aux factures. Exemple : Page du modèle audio-vers-audio Stable Audio 2.5.
Ce qui modifie couramment le coût réel (souvent dépendant du fournisseur, donc à considérer comme une déduction jusqu'à confirmation) :
Dépassements de durée : un contenu audio plus long peut coûter plus cher même si l'interface utilisateur affiche un seul chiffre.
Nouvelles tentatives : les nouvelles tentatives de réseau ou les délais d'attente peuvent créer des tâches en double si vous n'utilisez pas l'idempotence.
Modifications des paramètres : les modes "haute qualité", les passes supplémentaires ou les fonctionnalités avancées peuvent modifier la facturation.
Traitement par lots : la génération de 4 variations en un seul appel par rapport à 4 appels distincts peut être tarifée différemment (dépend de la conception de l'API).
Si vous souhaitez des dépenses prévisibles, enregistrez : le nom du point de terminaison, la durée, la taille de la charge utile, l’ID de la tâche et les unités facturées finales par requête, puis rapprochez-les chaque semaine.
Prix de Stable Audio 2.0 en 2026 : est-ce un forfait distinct et comment le vérifier ?
Les gens recherchent « tarification stable audio 2.0 2026 » parce qu'ils essaient de déterminer si la version « 2.0 » est facturée différemment des versions plus récentes (comme la 2.5) ou si elle est intégrée à un tableau de crédits unifié. L'approche la plus sûre est de ne pas supposer, mais de vérifier en utilisant une méthode reproductible.
Voici un flux de vérification clair :
Commencez par les mises à jour officielles des prix : consultez la page de mise à jour des prix de Stability AI pour savoir comment les crédits sont liés aux modèles et si les noms de version sont explicitement mentionnés : Mise à jour des prix de l'API.
Confirmez le nom/la version du modèle auprès de votre fournisseur : recherchez l'identifiant exact du modèle (par exemple, "stable-audio-2.5" vs "stable-audio-2.0") dans la liste des points de terminaison et la documentation.
Vérifiez sur la page de facturation/la facture : identifiez le SKU/l'identifiant de modèle qui est réellement facturé lorsque vous effectuez une génération de test.
Conservez des preuves pour votre équipe : conservez un instantané (date + URL) de la page de tarification et de l'identifiant du modèle que vous avez utilisé afin que les discussions sur les prix ne deviennent pas des devinettes par la suite.
Cette approche fonctionne que vous utilisiez une surface d'API officielle ou une place de marché partenaire, car dans les deux cas, le « prix réel » est ce que le système de facturation enregistre pour l'ID de modèle que vous avez exécuté.
Si vous ne trouvez pas les tarifs de Stable Audio 2.0 : raisons possibles (et que faire)
Si vous ne trouvez pas de ligne distincte pour la version 2.0, c'est généralement à cause de l'un de ces scénarios :
Regroupement des versions : les prix sont indiqués sous une catégorie plus large « Stable Audio » ou « Audio » au lieu d’une étiquette « 2.0 ».
Dépréciation ou changement de nom du modèle : la plateforme a peut-être déplacé les utilisateurs vers un ID de modèle plus récent sans mettre l’accent sur l’ancien nom.
Point d’entrée différent : la surface de produit officielle et une surface partenaire peuvent afficher les prix différemment.
Conditions réservées aux entreprises (inférence) : certains droits d’utilisation ou certains prix peuvent être négociés par le biais de ventes plutôt que de tableaux publics.
Que faire ensuite :
Contactez l'assistance de la plateforme avec votre identifiant de modèle, votre identifiant de requête et une capture d'écran de l'endroit où vous vous attendiez à voir les prix.
Effectuez un test contrôlé (une requête) et vérifiez comment il apparaît sur la facture/l'exportation.
Documentez le résultat dans vos notes d'ingénierie, y compris la date, au cas où les prix changeraient à nouveau.
Licences et utilisation commerciale : ce que les équipes doivent vérifier avant de publier de l'audio
Avant de publier tout contenu généré avec Stable Audio, veuillez confirmer les conditions de licence et d'utilisation commerciale pour la surface exacte que vous avez utilisée (plateforme officielle ou plateforme partenaire). Les conditions peuvent varier selon le fournisseur et le plan, il est donc important de toujours les vérifier sur les pages de conditions pertinentes plutôt que de se fier aux résumés de la communauté.
Une liste de contrôle de conformité pratique pour les équipes :
Confirmer si l'utilisation commerciale est autorisée dans votre plan et via le point de terminaison choisi.
Confirmer les exigences d'attribution (le cas échéant) pour l'audio publié.
Confirmer si vous pouvez utiliser les sorties dans des publicités, des jeux, des podcasts ou des bibliothèques de ressources (les conditions diffèrent souvent selon le type de distribution).
Confirmer le traitement des données : si les invites/entrées audio sont conservées et si elles peuvent être utilisées pour la formation (spécifique au fournisseur).
Confirmer votre politique interne concernant le contenu interdit (par exemple, l'usurpation d'identité, les mélodies protégées par le droit d'auteur, les imitations de sons de marque).
Ceci ne constitue pas un avis juridique — considérez-le comme une liste de contrôle opérationnelle pour vous assurer de poser les bonnes questions dès le début.
Stable Audio contre Suno contre Udio : quand Stable Audio est le choix le plus sûr
Lorsque les équipes comparent Stable Audio avec Suno et Udio, le "meilleur" choix dépend des contraintes de déploiement, du flux de travail et de la tolérance au risque, et pas seulement de la qualité brute de la sortie. Stable Audio devient le choix le plus sûr dans quelques cas courants :
Vous avez besoin de signaux plus clairs concernant le déploiement et la portabilité (par exemple, l'intérêt pour des modèles audio plus petits/compatibles avec la périphérie, comme indiqué dans des articles tels que TechCrunch : Stability AI releases an audio generating model that can run on smartphones).
Vous avez besoin d'un chemin d'intégration API-first avec des ID de modèle explicites et une observabilité prévisible.
Votre organisation est particulièrement sensible au risque de propriété intellectuelle et souhaite fonder ses décisions sur des conditions documentées et des rapports réputés, et pas seulement sur des anecdotes de la communauté.
Une table de décision simple :
Pour une autre perspective sur les différences de sortie, vous pouvez également consulter les comparaisons de la communauté (puis valider en testant vos propres invites) : Aperçu comparatif Udio vs Suno.
Les questions les plus fréquemment posées concernent : la qualité, le chant/les paroles et le risque de propriété intellectuelle.
Q : Stable Audio est-il de « haute qualité » par rapport aux autres générateurs ?
R : La qualité dépend fortement du point de terminaison/de la version, de la durée et de la discipline d’invite. Pour la plupart des équipes, la mesure pratique est « combien de générations jusqu’à ce que nous obtenions une sortie acceptable », car cela influe à la fois sur l’UX et sur le coût.
Q : Stable Audio peut-il générer des voix et des paroles ?
R : Cela dépend de la version spécifique de Stable Audio et de la surface de la plateforme que vous utilisez (certains points de terminaison se concentrent sur la conception instrumentale/sonore). Vérifiez la liste des fonctionnalités dans la documentation de votre fournisseur et testez avec un court ensemble d’évaluation.
Q: Quel est son degré de contrôle (structure, tempo, instrumentation) ?
A: Le contrôle s’améliore lorsque vous (1) spécifiez le tempo/groove, (2) limitez l’instrumentation, (3) maintenez une durée courte pendant l’itération et (4) utilisez l’audio vers audio lorsque vous devez préserver le timing/la structure.
Q: Qu'en est-il du risque lié à la propriété intellectuelle ?
R: Aucun modèle n'élimine le risque. Votre position opérationnelle la plus sûre est la suivante : respectez les conditions de la plateforme, évitez de demander des artistes vivants « exactement semblables » ou des chansons reconnaissables, conservez des journaux pour la provenance et exécutez un processus d'examen pour les versions commerciales. Si vous évaluez les orientations de la recherche et l'encadrement des risques, vous pouvez également parcourir les discussions universitaires pertinentes (pour le contexte technique) : https://arxiv.org/html/2506.19085v1
Dépannage des sorties Stable Audio : solutions pour les 5 pannes les plus fréquentes
La plupart des « échecs » audio stables peuvent être corrigés avec des contraintes plus strictes, des boucles d’itération plus courtes et une meilleure validation des entrées. Si vous créez une fonctionnalité (et pas seulement si vous expérimentez), considérez le dépannage comme faisant partie de la conception de votre produit : définissez une sortie acceptable, appliquez des contraintes de requête et enregistrez tout.
Voici les cinq problèmes les plus courants et deux ajustements immédiats pour chacun :
1) La sortie s'éloigne de la demande (mauvais genre/instruments)
Ajustement A : Déplacer les contraintes clés au début : « Instrumental, sans voix. 90 BPM. Batterie acoustique + basse électrique. »
Ajustement B : Ajouter des contraintes négatives : « éviter les supersaws EDM, éviter les cordes orchestrales. »
2) La musique semble déstructurée ou décousue
Ajustement A : Raccourcir la durée pendant l’itération (par exemple, 8 à 15 secondes) et augmenter l’échelle uniquement après avoir obtenu le motif approprié.
Ajustement B : Spécifier les repères de structure : « courte introduction, boucle principale, fin propre » (le comportement pris en charge varie, mais cela aide souvent).
3) Écrêtage, aigus agressifs ou distorsion
Ajustement A : Ajouter des contraintes de mixage : « pas d’écrêtage, aigus contrôlés, volume sonore modéré ».
Ajustement B : Normaliser votre audio d’entrée (pour l’audio vers audio) et éviter les références extrêmement fortes.
4) Durée incorrecte (trop courte/trop longue)
Ajustement A : Assurez-vous de définir le nom/l’unité de champ de durée correct à partir de la documentation.
Ajustement B : Si le point de terminaison a une durée maximale, divisez les requêtes en segments et assemblez-les en aval.
5) Incohérence de style entre les variantes
Ajustement A : Utiliser un modèle d’invite fixe et conserver une seule « ligne de style » constante dans toutes les requêtes.
Ajustement B : Préférer l’audio-vers-audio avec un clip de référence cohérent pour ancrer le timbre et le groove (lorsque disponible).
Pour des conseils pratiques sur le workflow autour de la génération et de l'itération Stable Audio, le tutoriel Comfy et les guides pratiques sont également des références utiles : Tutoriel Stable Audio et une présentation axée sur les praticiens sur DigitalOcean : https://www.digitalocean.com/community/tutorials/stable-audio-music-generation
Déboguer les erreurs d'API : délais d'attente, limitations de débit et entrées malformées
Lorsque la qualité de la sortie est bonne mais que votre intégration est instable, déboguez comme un ingénieur API, pas comme un ingénieur de prompt. Utilisez une liste de contrôle des incidents cohérente :
Enregistrer un identifiant de requête (à partir de la réponse du fournisseur) et l'attacher à l'identifiant de tâche de votre application.
Stocker la charge utile brute que vous avez envoyée (masquer les secrets) afin de pouvoir la reproduire.
Valider les entrées avant l'envoi :
format audio, durée et taille du fichier (conformément à la documentation de votre point de terminaison)
champs obligatoires présents et dans les plages autorisées
Implémenter un backoff pour les 429 : backoff exponentiel + gigue ; limiter le nombre maximal de tentatives ; éviter les effets de troupeau.
Gérer explicitement les délais d'attente :
utiliser la soumission de tâche asynchrone si disponible
augmenter le délai d'attente du client uniquement si le fournisseur le recommande
traiter les délais d'attente comme un « état inconnu » et rapprocher par identifiant de tâche, et non en réessayant aveuglément
Si vous utilisez le point de terminaison audio-vers-audio Stable Audio 2.5 sur un fournisseur partenaire, gardez la référence API ouverte pendant que vous déboguez les noms de champs et les contraintes : Documentation de l’API audio-vers-audio Stable Audio 2.5.
Créez de la musique prête à être publiée en quelques minutes 🎵
Passez rapidement de l'idée au morceau fini. Aucune compétence technique n'est requise.