If you’re evaluating ElevenLabs pricing, you probably want one clear answer to four questions: what “credits” really mean, what the free tier can (and can’t) do, how the ElevenLabs API is billed, and whether there’s real ElevenLabs SSML support. Good fit: creators who need natural narration, product teams adding TTS to an app, or studios that care about voice quality more than the absolute lowest cost. Not ideal: teams needing fully predictable per-minute pricing, heavy SSML-driven prosody control for every sentence, or extremely high-volume audio at the lowest possible unit rate.
ElevenLabs pricing can look simple at first, but the real cost depends on how credits map to characters, which models you use, and whether your usage is personal, team-based, or API-driven. In the sections below, we’ll break down how ElevenLabs pricing plans actually work, what the free tier is good for, and how to estimate your likely spend before you commit.

How does ElevenLabs pricing work (credits, characters, and models)?
At a high level, ElevenLabs pricing is credit-based, but your actual mental model should be: characters → model choice → audio duration. You see credits in the dashboard, yet what you feel in production is “how many minutes of audio did I generate” and “how often did I have to regenerate because of revisions.”
Most plans combine two layers: 1) A subscription allowance (your monthly/annual included credits), and 2) Optional overage via pay-as-you-go top ups (often called PAYG Top Ups), which helps prevent your app or workflow from suddenly stopping when included credits are depleted.
Because the “effective cost” changes by model and use case, the most reliable workflow is to estimate from expected monthly characters (scripts, prompts, and retries included), then validate with a small pilot.
Credit-to-audio mapping: why model choice changes your effective cost
Model choice is the hidden lever in elevenlabs pricing plans. Different models trade off quality, latency, and how efficiently credits translate into audio. ElevenLabs publishes model details (including “Approximate audio duration”) in its documentation—use that as your north star when mapping budget to minutes of output: ElevenLabs models documentation.
Here’s a practical “planning table” you can use before you lock a plan (exact durations vary by voice, settings, and content density—confirm in the docs above):
How this affects your day-to-day:
Narration (YouTube / courses): You usually care about smoothness and fewer re-renders—higher quality often saves time even if it costs more per minute.
Dialogue (apps / agents): Your cost can be dominated by volume + retries (timeouts, user interruptions, streaming restarts).
Low-latency: You may spend more on “non-content characters” (short prompts, filler, re-asks) than you expect.
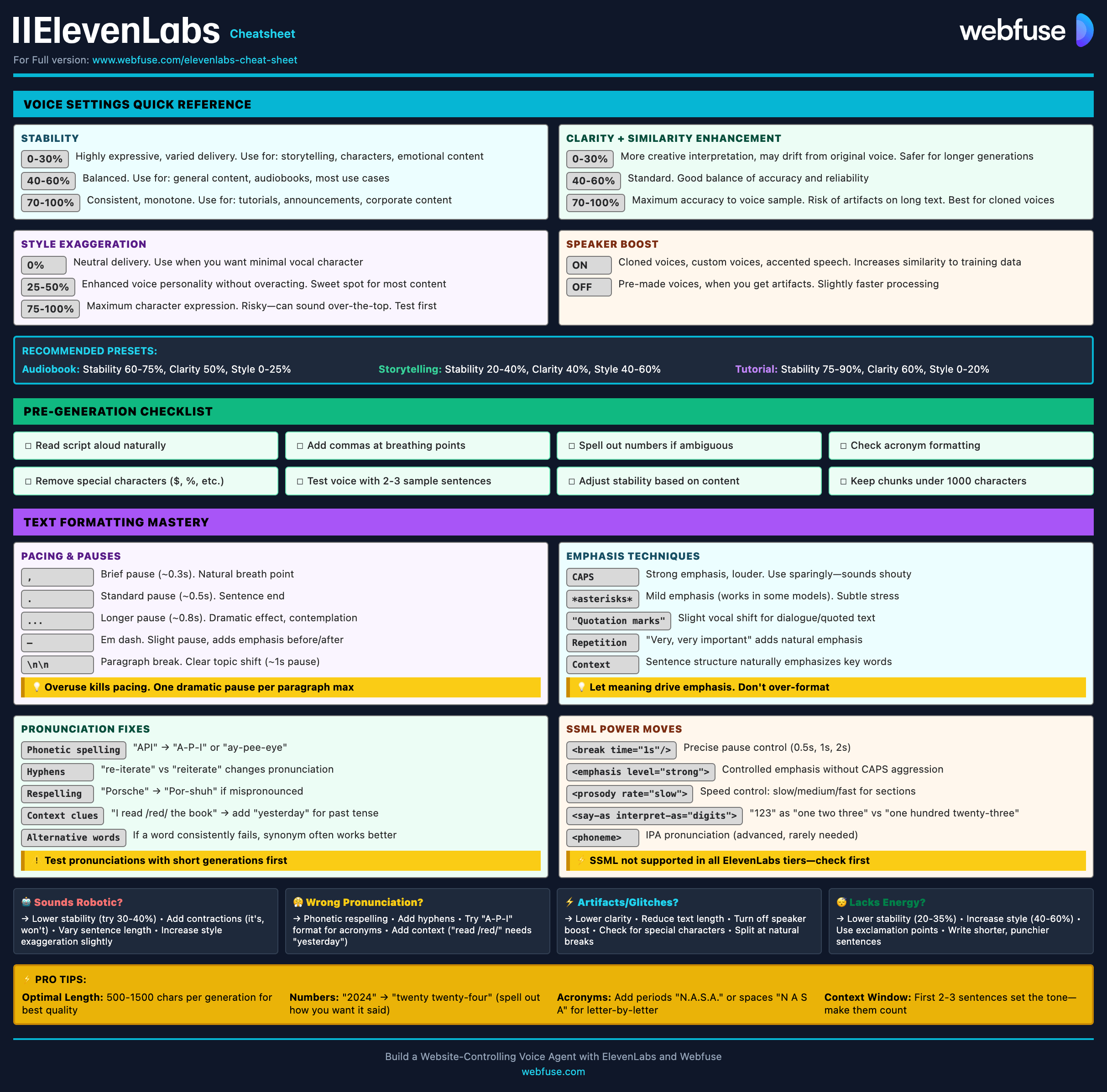
When pay-as-you-go top ups kick in (and what happens when credits run out)
If you’re building anything user-facing, elevenlabs api pricing risk is less about “price per character” and more about what happens at the exact moment you hit your allowance.
ElevenLabs describes PAYG mechanics in its admin docs: Pay-as-you-go top ups overview. In practice, plan around these behaviors:
Consumption order: Subscription credits are typically consumed first; PAYG top ups are used when your included allowance is exhausted (or when you’ve enabled top ups to avoid interruptions).
What “run out” looks like: Without PAYG enabled (or without remaining top-up balance), API calls may fail once you hit your limit—this can break production user flows.
Upgrades and changes: Billing cycles and included allowances reset on plan terms; top-up behavior and remaining balances can follow rules that differ from subscription credits. Treat upgrades/downgrades as a billing-event and verify in the admin panel.
Common “gotchas” (based on how teams usually misconfigure usage):
You assumed a subscription means “no extra charges,” but PAYG was enabled to prevent downtime.
A staging key was accidentally used in production, doubling usage and triggering PAYG.
You didn’t include regenerations (edits, retries, A/B voice tests) in the budget, so you hit the ceiling early.
If you enable PAYG to protect uptime, you also need strong monitoring and per-key limits—otherwise a bug (or leaked key) can create surprise spend.
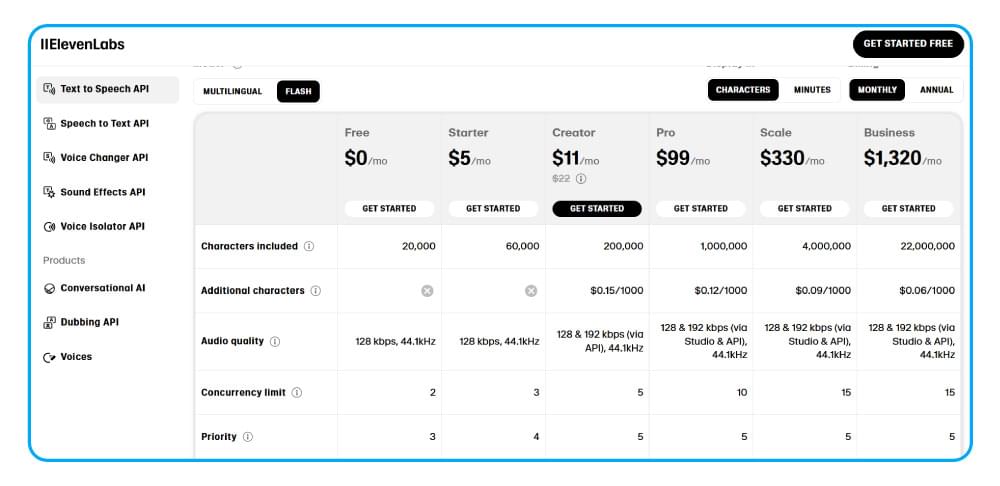
ElevenLabs pricing plans: which plan should you pick?
The fastest way to choose among elevenlabs pricing plans is to ignore plan names and start with who you are and how you’ll use audio—trialing, publishing content, collaborating, or embedding TTS into a product.
Use this plan comparison table as a “fit map” (don’t treat it as a promise of specific quotas—those change; confirm the current allowances and licensing terms on the official plan page or plan description you’re viewing).
A practical selection rule:
Choose a creator plan when your bottleneck is “minutes per month” and a single person is producing.
Choose a team plan when your bottleneck is approvals, shared voice assets, and governance.
Choose an API-first setup when your bottleneck is reliability, monitoring, and predictable scaling.
Monthly vs annual billing: how to decide without overpaying
When you see “monthly vs annual,” the decision is less about discount percentage and more about confidence in your usage curve.
Use these three rules of thumb: 1) Not sure yet → go monthly. You’ll learn your real character volume, re-render rate, and preferred model faster than you think. 2) Proven workflow → consider annual. If you already publish on a schedule (or you’ve shipped the feature), annual can reduce admin and budgeting friction. 3) Seasonal output → stay monthly. Launch campaigns, course drops, and holiday peaks often create uneven usage.
Extra considerations (especially for teams):
Budget lock + procurement: Annual can simplify invoices and approvals, but only if your usage is stable.
Risk management: Monthly reduces the penalty of switching models/tools if requirements change.
ElevenLabs pricing free tier: what you can do (and what you can’t)
The elevenlabs pricing free tier is best viewed as an evaluation sandbox—not a long-term production plan. It can absolutely help you judge voice realism, but you’ll hit limits faster than expected if you test broadly.
What you can do
Assess voice naturalness: cadence, breathiness, pronunciation, and how the voice handles your domain terms.
Compare models/voices: run the same script through different options to find a “house voice.”
Prototype a workflow: script → generate → revise → export (at small scale).
What you can’t (or shouldn’t) rely on
Sustained publishing: long videos, serialized podcasts, or frequent re-takes will typically exceed free allowances.
Clear commercial certainty: commercial rights and licensing often differ between free and paid tiers—always verify the current terms for the elevenlabs pricing free plan before monetizing output.
Full feature parity: some quality, speed, or project features may be gated.
Who it’s for
Creators validating “Is this voice good enough for my channel?”
PMs and engineers running a feasibility check before implementing the ElevenLabs API
Teams building a short demo to align stakeholders
A complete free-tier evaluation checklist (fast but thorough):
Test 3 script types:
1) Straight narration (60–120 seconds) 2) High-energy promo copy (30–60 seconds) 3) Difficult pronunciation list (names, acronyms, product terms)
Test 2 model modes: one quality-focused, one low-latency (if relevant)
Test delivery controls: slower vs faster pacing, more/less expressive reads (where available)
Measure revision rate: how often you regenerate to get an acceptable take
Track “regenerations per finished minute.” For many teams, retries cost more than the first pass.

Free plan limitations users complain about (community-reported)
Community threads about the elevenlabs pricing free plan often cluster around expectations vs reality. Based on user discussions (individual experiences vary), common themes include:
“I ran out faster than expected.” Many users underestimate how quickly credits go when they regenerate takes, test voices, or iterate on scripts.
Perceived feature gaps. Some users feel the free tier doesn’t reflect paid-tier quality/controls, making evaluation harder.
Confusion about rules. Users sometimes describe the limits or gating as unclear until they hit a wall.
Mismatch with “reader” use cases. When people want continuous listening (articles, long documents), free-tier allowances can feel especially tight.
Treat these as signals to test deliberately: don’t “spray and pray” with dozens of small generations; run a structured evaluation so you learn what matters.
ElevenLabs API pricing: estimate your bill before you ship
For elevenlabs api pricing, accurate estimation comes from turning “text volume” into “monthly characters” and then adding the two big multipliers: model choice and operational overhead (concurrency + retries).
A good pre-launch estimate breaks into three variables:
1) Character volume (the base):
average characters per request (including punctuation and spaces)
number of requests per user per day
monthly active usage (DAU/MAU)
2) Model selection (the multiplier):
higher quality or special-purpose models can change effective credits-per-minute
different products (batch narration vs interactive chat) push you toward different models
3) Concurrency + retries (the silent multiplier):
timeouts, streaming restarts, and “user interrupted—regenerate” flows
A/B tests and voice experiments in production
A practical DAU → cost estimation path (PM-friendly):
Step 1: Estimate DAU who will use voice (not total DAU)
Step 2: Estimate requests per voice user per day
Step 3: Estimate average characters per request
Step 4: Monthly characters = DAU_voice × requests/day × characters/request × 30
Step 5: Add overhead = monthly characters × (1 + retry_rate + experimentation_factor)
Step 6: Map characters to credits/cost using your chosen plan + model behavior
Example (purely illustrative math, not pricing): If 5,000 voice-users/day × 4 requests/day × 250 characters/request × 30 days = 150M characters/month, then a 10% retry rate and 5% experimentation factor pushes you to ~172.5M “billed characters equivalent.”
If you’re still deciding whether to build voice in-house or mix vendors, it can help to skim broader tooling comparisons (for context on tradeoffs rather than exact costs): overview of ElevenLabs alternatives.
Track character usage with the API (so finance doesn’t get surprised)
You don’t want your first “real” usage report to come from a billing email. Instrument usage from day one using the official endpoint: Usage API reference.
Monitoring metrics worth tracking (minimum set):
Daily characters generated (and 7-day moving average)
Peak-day usage (p95 daily consumption)
Error rate and retry rate (especially timeouts)
Per-user distribution (top 1% consumers vs median)
Environment split (staging vs production)
Model split (which models are driving spend)
A simple rollout plan that prevents surprises: 1) Log characters per request at the app layer (before calling TTS). 2) Pull official usage daily and reconcile with your logs. 3) Run a 7-day “canary” with a small % of traffic, then scale.
If you want a quick test call, the docs include copy-paste examples; conceptually it looks like: curl -X GET "https://api.elevenlabs.io/v1/usage/character-stats" -H "xi-api-key: $ELEVENLABS_API_KEY"
Put safety rails on keys: per-key limits for teams and staging
Most “runaway bills” come from keys—not models. Lock down your elevenlabs api usage with three practices:
1) Least privilege by default Create separate keys/service accounts for each app or service. Don’t reuse a personal key in production.
2) Environment isolation (staging vs prod)
Staging key: low character cap, used only in CI/tests
Production key: monitored, rotated, and stored in a secrets manager
This makes it harder for a QA loop or load test to drain real credits.
3) Per-key character limits (character_limit) Use the API key update endpoint to set enforceable caps: Update API keys reference. A cap turns “infinite blast radius” into a contained incident.
Assume keys will leak eventually (logs, screenshots, misconfigured repos). Per-key limits + rotation is what turns a leak into a minor issue instead of a major bill.
ElevenLabs SSML support: what’s supported and practical workarounds
Yes—there is ElevenLabs SSML support, but it’s easy to miss because it’s not always “on” by default in every integration. In practice, SSML is most useful when you need repeatable control over pauses, emphasis, and pronunciation, especially for:
e-learning narration (consistent pacing)
product terms and acronyms
scripted dialogue timing
That said, many teams find that if the goal is “slightly longer pause” or “cleaner phrasing,” plain-text techniques can be more stable:
add punctuation (comma / em dash)
split long sentences into two
move parentheticals into separate sentences
This is often more predictable than relying on a complex SSML tree in dynamic, user-generated text.
Enabling SSML parsing: the setting many people miss
In some stacks, SSML parsing requires an explicit toggle like enable_ssml_parsing. For example, LiveKit’s ElevenLabs TTS integration documents this as a configuration option: LiveKit ElevenLabs TTS SSML setting.
What to watch for:
Default behavior: If SSML parsing is disabled, tags may be spoken literally or stripped unexpectedly.
When to enable: Use it for curated scripts (courses, ads, tutorials) more than raw user text.
Validation: Always listen to a “nasty” test case (nested tags, odd punctuation, numbers).
Common SSML patterns (examples are standard SSML concepts; exact support can vary by engine/version):
Pauses:
<break time="500ms"/>Emphasis:
<emphasis level="moderate">important</emphasis>Spelling/reading style:
<say-as interpret-as="characters">API</say-as>
If your output sounds inconsistent even with SSML enabled, fall back to simpler text formatting first—SSML should be the last layer of control, not the first.
Is ElevenLabs worth it vs alternatives at the same budget?
Whether elevenlabs is “worth it” at your budget depends on which constraint matters most:
Naturalness & expressiveness: If your brand depends on premium narration quality, paying a bit more per finished minute can be worth it.
Low-latency dialogue: If you’re building interactive agents, you’ll judge value by responsiveness and stability under concurrency.
Editing workflow: Some teams value tools that reduce revisions (fewer regenerations) more than a lower headline price.
Commercial licensing: Paid tiers often make commercialization simpler—but you still must verify current terms.
Integration effort: API docs, key management, usage tracking, and safety rails are real engineering cost.
Unit economics: Your real cost is “characters × retries × model mix,” not the plan label.
If your project is broader than voice—like turning ideas into music, hooks, or melody-driven content—it may be more efficient to pair TTS with a dedicated creation tool. You can explore MelodyCraft for music-first generation and iteration, then combine the results with voice workflows when needed.
FAQs people ask before subscribing (free tier, commercial use, API, SSML)
Q: Is ElevenLabs free?
A: There’s typically a free tier meant for evaluation and light use. Limits and included features can change, so treat it as a trial environment.
Q: Can I use outputs commercially on the free tier?
A: Commercial rights often differ between free vs paid plans. Check the current licensing terms shown in your account/plan page before publishing monetized content.
Q: Do credits roll over?
A: Many subscriptions reset on a billing cycle, and rollover rules (if any) can vary. Confirm the current behavior in your subscription settings.
Q: Do I need a paid plan for API access?
A: API access is commonly tied to certain plans and may have account requirements. If API access is central to your use case, confirm it before you commit.
Q: How do I reduce ElevenLabs API costs without hurting quality?
A: Reduce retries (better prompts/scripts), pick a model that matches your latency/quality needs, cache repeated outputs, and split long text into stable segments to avoid regenerating full paragraphs.
Q: What triggers pay-as-you-go top ups?
A: PAYG typically applies when subscription credits are exhausted (or when configured to prevent downtime). Review the official PAYG behavior here: pay-as-you-go top ups documentation.
Q: Does ElevenLabs support SSML?
A: Yes, SSML parsing is supported in many setups, but may require an explicit enable switch such as enable_ssml_parsing in certain integrations: SSML enable setting reference.
Q: What’s the fastest way to estimate which plan I need?
A: Estimate monthly characters from your scripts/DAU, add a retry factor, then validate with a 1–2 week pilot using your intended model mix.
Make Ready-to-Publish Music in Minutes 🎵
Go from idea to finished track quickly. No technical skills required.